
A new era of productivity: Prompt Architected Software
4 September 2023

Amidst the generative AI boom, enterprises spanning all industries are bolstering their IT department. Innovation directors are asking us how they can leverage chatbots, or Large Language Models (LLMs), and ride this wave.
Engineering a well-structured prompt is crucial to obtaining accurate and relevant responses from chatbots. However, individual prompts are only half the magic. To fully support your company’s workflows, an overarching architecture, designed to maximise value from a large selection of prompts, is essential.
We introduced the term ‘prompt architecting’ at the end of our past article about building your ‘own ChatGPT’ or fine-tuning an LLM. We explained why fine-tuning or building an LLM from scratch are both a lot of work and usually unnecessary.
In short, creating an LLM from scratch is an ambitious, expensive, and highly risky undertaking recommended primarily to those who plan to compete with the likes of Google or Microsoft. Fine-tuning is a comparatively smaller job, as it only involves retraining a portion of an LLM with new data. But, it is still unnecessarily arduous unless you really need an on-prem LLM (you’d know if you do). Our proposal for the route advisable for the majority of enterprises was prompt architecting with an API-enabled version of an existing model.
Put simply, ‘prompt architecting’ is to prompt engineering what software architecture is to software engineering. Instead of engineering individual prompts that achieve a single goal, we create entire pieces of software that chain, combine, and even generate tens, if not hundreds, of prompts, on the fly to achieve a desired outcome.
The goal of this article is to demystify the term ‘prompt architecting’. We commence with the origins of its name. Then, we explain the two main steps. We finish off with an HR chatbot case study to see how it looks in practice.
Where does ‘prompt architecting’ get its name: its classical roots
Architecture, whether in the context of buildings, software, or prompts involves balancing factors such as functionality, user experience (UX), security, regulatory compliance, and aesthetics. For example, software architects focus on defining the high-level structure, components, and interactions within the system. This initial blueprint sets the foundation for the entire software project.
On the other hand, software engineering delves into the detailed implementation of the software architecture. Software engineering involves the nitty-gritty aspects of coding, testing, debugging, and optimising the software to bring the architectural vision to life.
Next, we look at the world of prompts.
What is prompt architecting?
Let’s apply the above train of thought to prompts (the text or image input we send to LLMs like ChatGPT).
Given the right sequence of prompts, LLMs are remarkably smart at bending to your will. This is why at Springbok, the first step in any of our projects is to design the appropriate prompt architecture for our client’s use case.
In this section, we explain Springbok’s approach to creating prompt architectures.
Let’s apply the above train of thought to prompts (the text or image input we send to LLMs like ChatGPT).
Given the right sequence of prompts, LLMs are remarkably smart at bending to your will. This is why at Springbok, the first step in any of our projects is to design the appropriate prompt architecture for our client’s use case.
In this section, we explain Springbok’s approach to creating prompt architectures.
Prompt engineering
‘Prompt engineering’ popularly refers to the process of crafting individual effective inputs, called ‘prompts’, for an LLM.
Typical goals for such activities include optimising the model’s response in terms of format, content, style, length or any number of other factors. Practically, prompt engineering involves framing the question in a specific way, adding context, or giving examples of output to guide the model to format its output similarly.
Prompt architecting
A prompt architecture at Springbok often consists of a data flow diagram, and a traditional software architecture diagram.
We consider the following aspects:
Functional requirements
We adapt the data flow architecture to the mode our client chooses for the output to be displayed as. You might have an intuitive dashboard, a conversational interface, or a document compliant with a provided template.
Non-functional requirements
There are also non-functional requirements: balancing cost-effectiveness while optimising performance, working around rate limits, and minimising latency. Not to be forgotten are ensuring security through robust authentication and authorisation, as well as adhering to data location requirements.
Integration with additional data sources
We consider the potential requirements for integrating the LLM with additional data sources. This may include databases for efficient data retrieval, Salesforce for CRM communication, various platforms for content compatibility, and Optical Character Recognition (OCR) capabilities for processing text from images or scanned documents.
Output quality control
We put measures in place to filter offensive language, align generated content with desired tone of voice and branding guidelines, and mitigate the risk of false or misleading information being generated through hallucination.
Analytics
We design mechanisms for collecting user feedback to improve the system’s performance, provide transparency in the decision-making process, gather usage statistics for data-driven decisions, and implement abuse detection mechanisms to prevent malicious use.
What does prompt architecting look like in practice? An HR chatbot case study
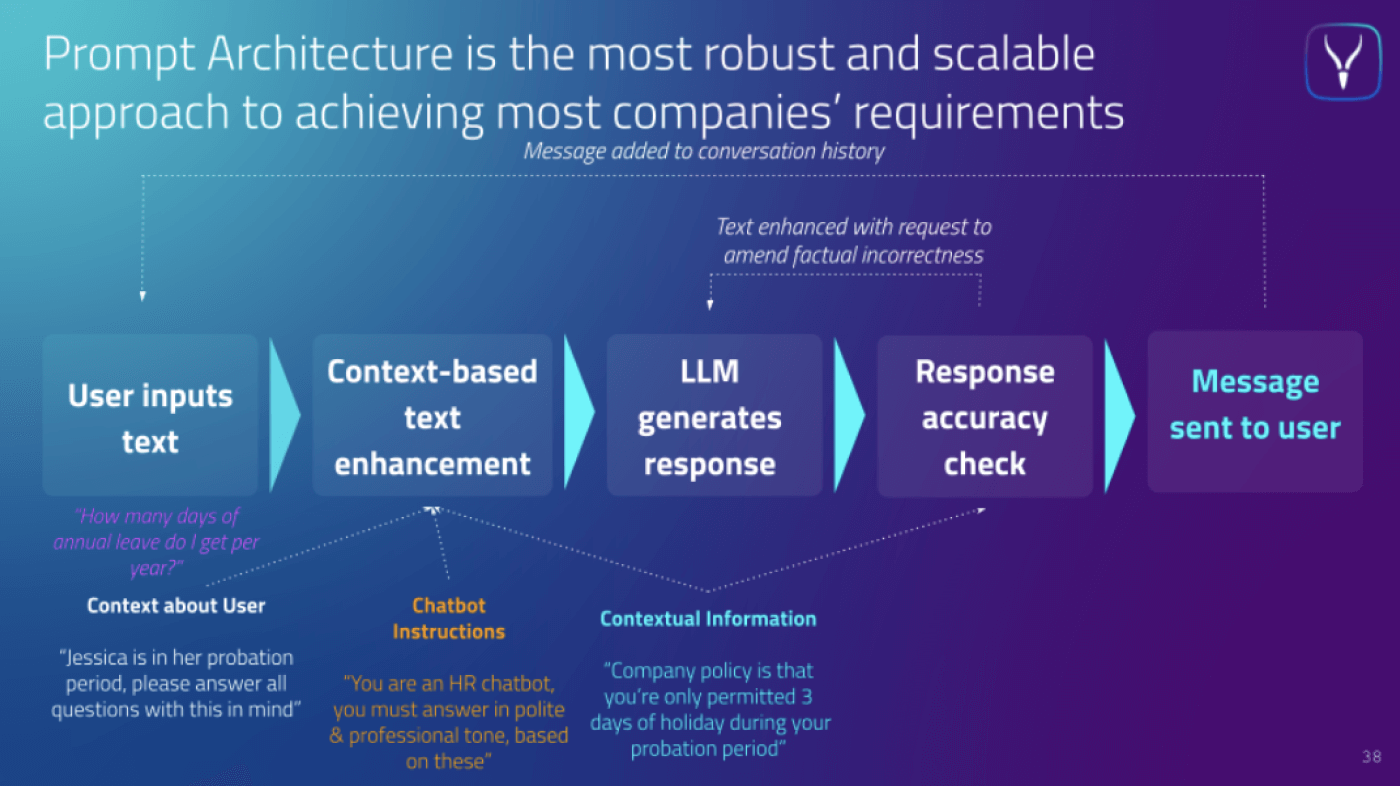
Let’s take a look at prompt architecting in a case study. In this section, we consider an HR chatbot that we are questioning about annual leave.
How do we bend LLMs to our will so that we can produce reproducible, reliable outcomes that help our customers both external and internal complete their productive endeavours?
People come to us wanting to achieve things like:
Lawyers: “I want to be able to automatically generate contracts based on my firm’s best practices”
Head of HR: “I want to be able to automatically answer HR-related employee queries based on our handbook”
Head of CX: “I want to automatically answer customer queries based on our product troubleshooting instructions”
Luckily, none of these use cases require fine-tuning to solve!
We advocate creating software products to cleverly use prompts to steer ChatGPT the way you want. ‘Prompt architecting’ is what we name this approach. It is similar to prompt engineering, but with a key difference.
Instead of engineering individual prompts that achieve a single goal, we create entire pieces of software that chain, combine, and even generate tens, if not hundreds, of prompts, on the fly to achieve a desired outcome.
How can I get started?
Either, you can have your own dedicated in-house generative AI team, or you can reach out to a technology partner like Springbok.
If you are interested in starting a conversation, reach out on victoria@springbok.ai We would be pleased to hear from you.
Other posts

Linklaters launches AI Sandbox following second global ideas campaign
Linklaters has launched an AI Sandbox which it says will allow the firm to quickly build out AI solutions and capitalise on the engagement and ideas from its people.

Linklaters staff pitch 50 ideas in supercharged AI strategy
Linklaters has announced the launch of an AI sandbox, a creative environment that will allow AI ideas to be brought, built and tested internally.

Linklaters joins forces with Springbok for its AI Sandbox
Global law firm Linklaters has launched an ‘AI Sandbox’, which will allow the firm to ‘quickly build out genAI solutions, many of which have stemmed from ideas suggested by its people’, they have announced.